What’s New in Flame 2025にもアップしていますが、もう少し詳しく説明します。
TimelineFX Timewarpノード
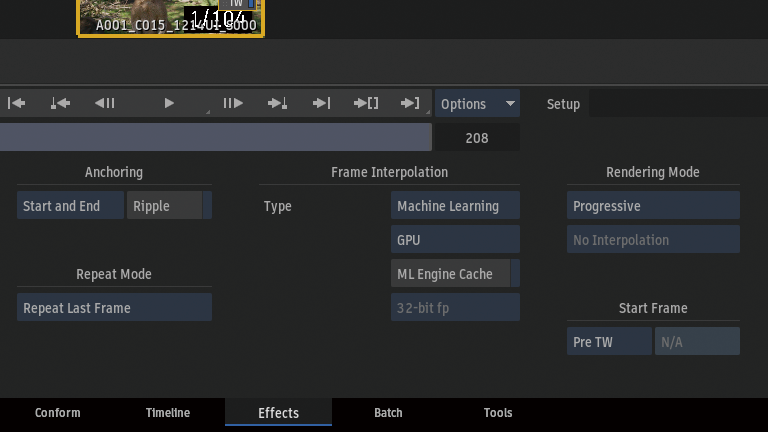
TimelineFX > Timewarpノードをセグメントに追加。
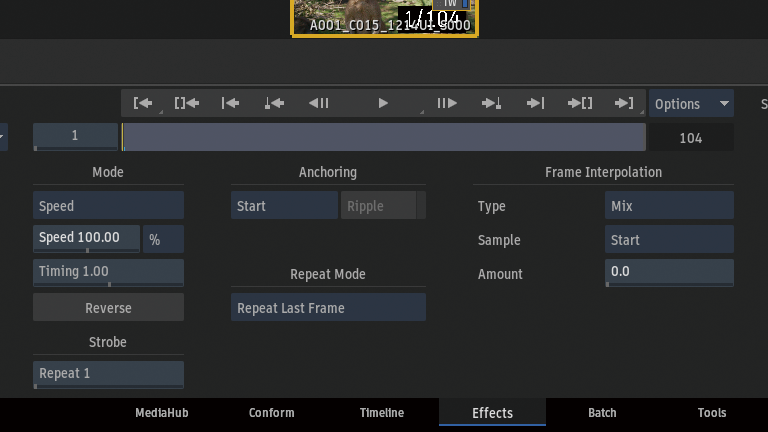
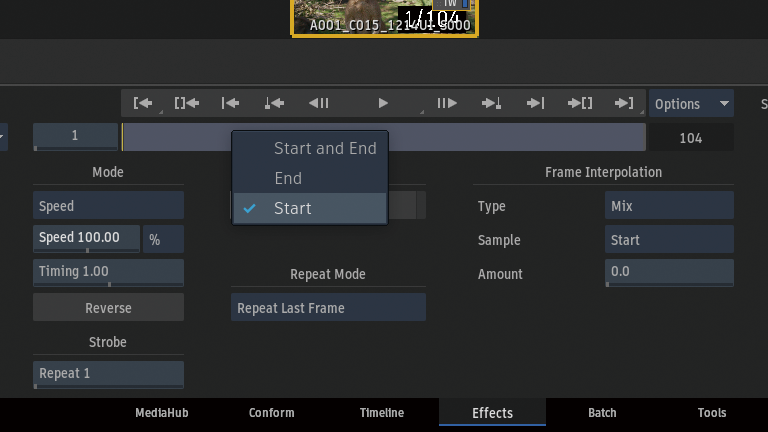
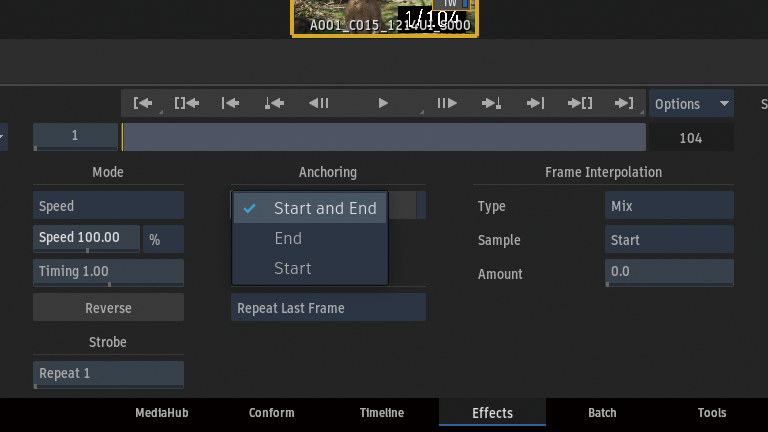
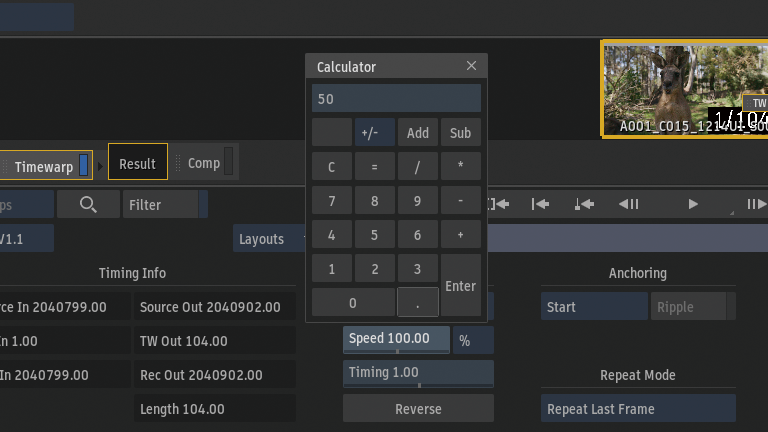
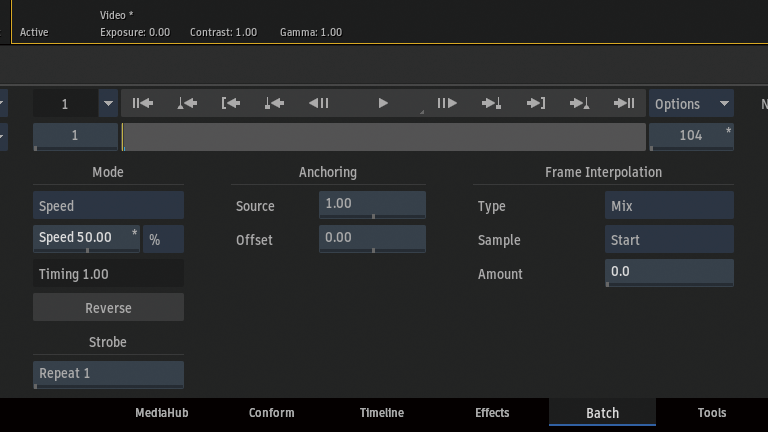
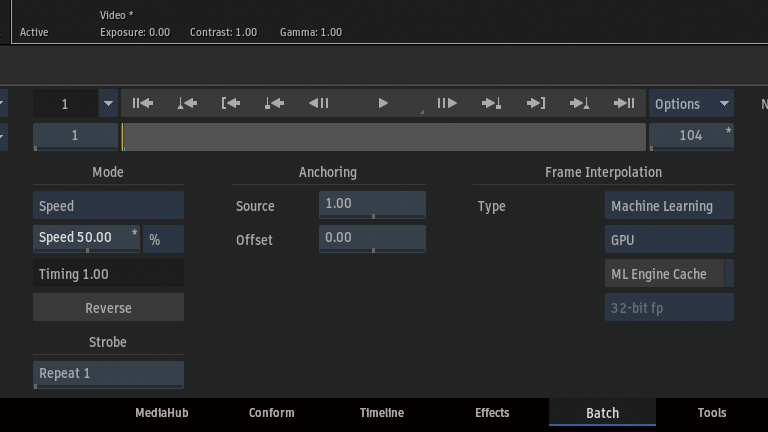
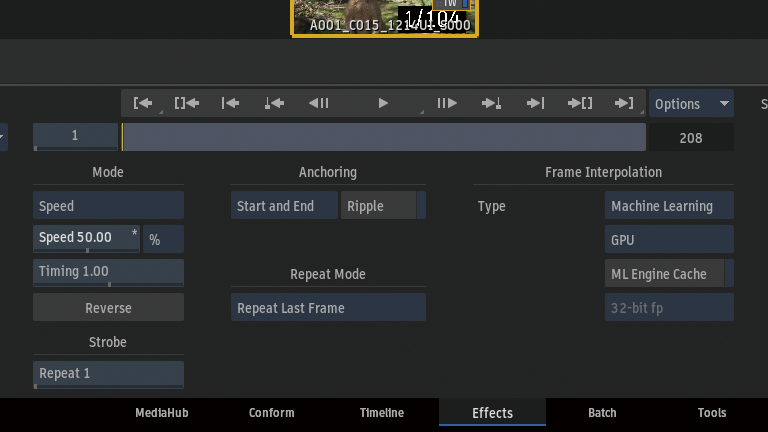
スピードを変更した時にデュレーションもマッチさせたいので、Anchoring > Start and Endを選択。
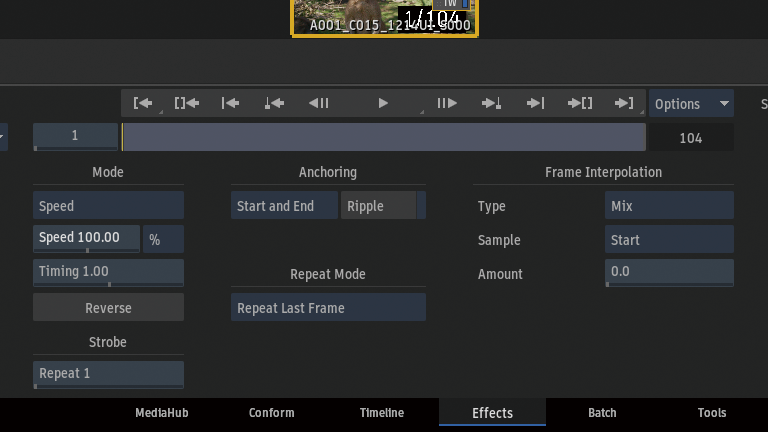
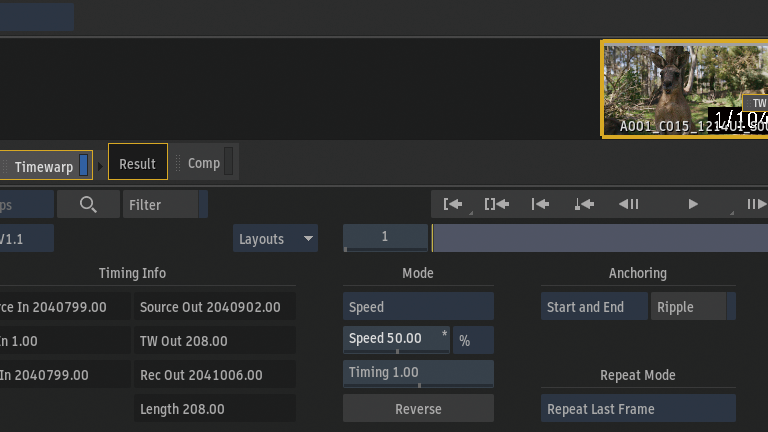
スピードを50%に変更。
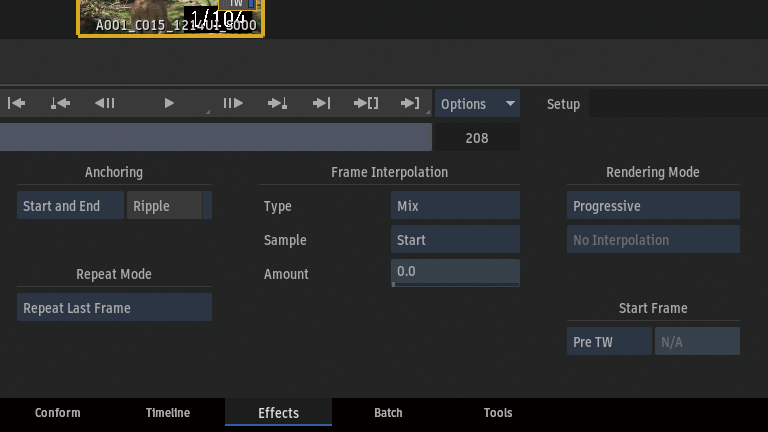
Frame InterpolationからMachine Learningを選択。
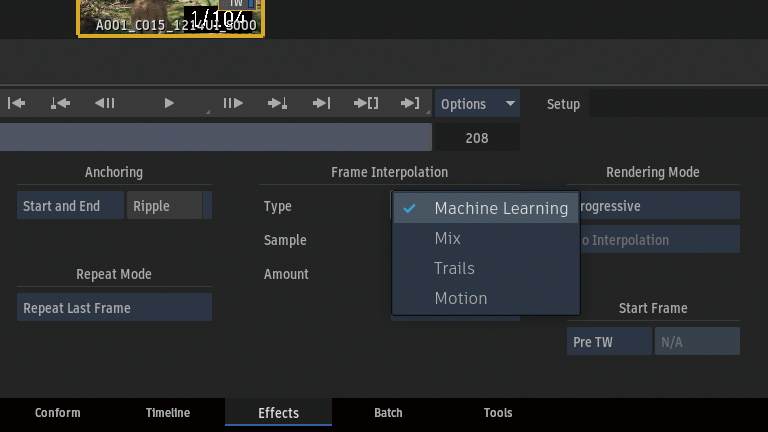
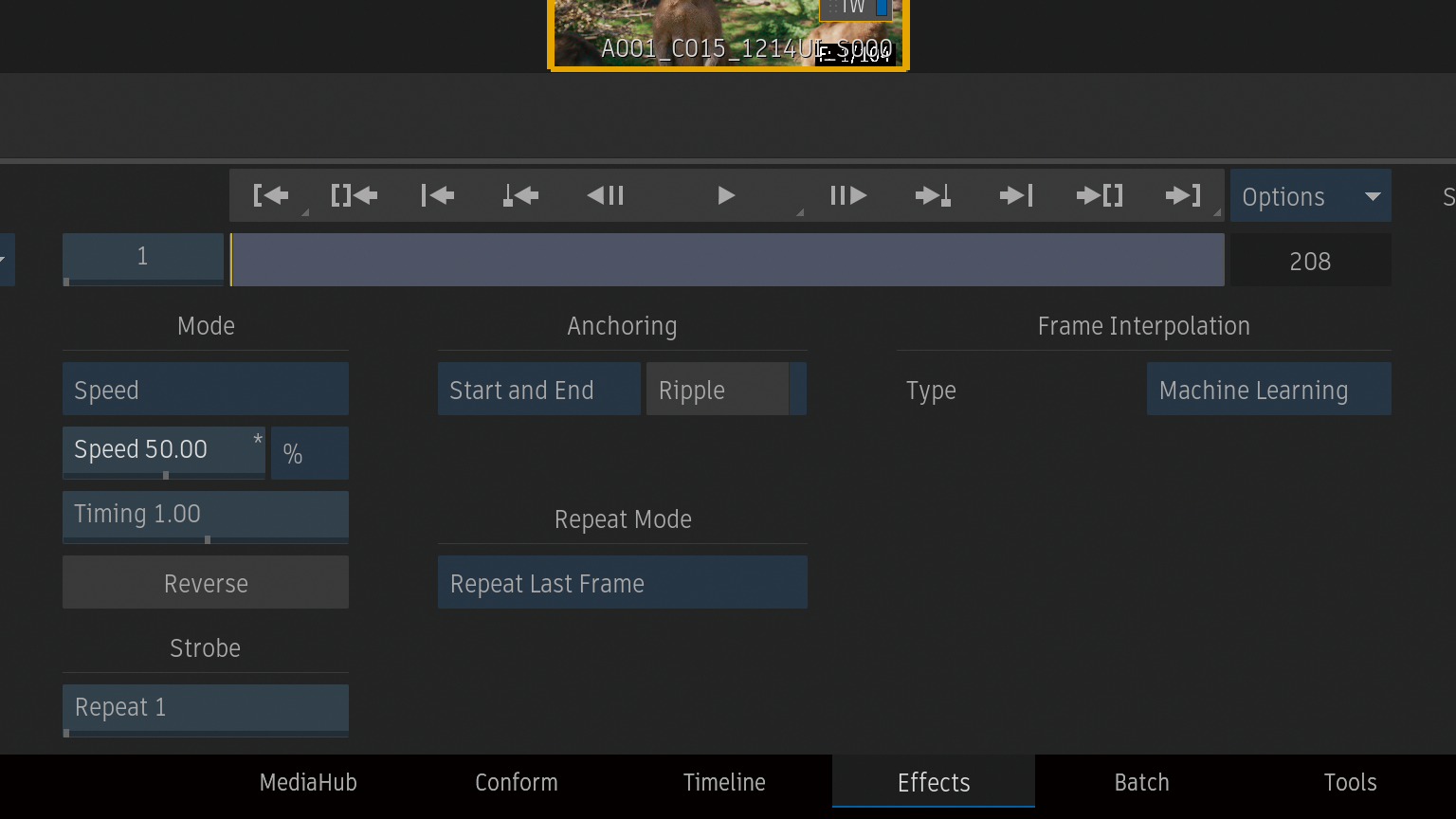
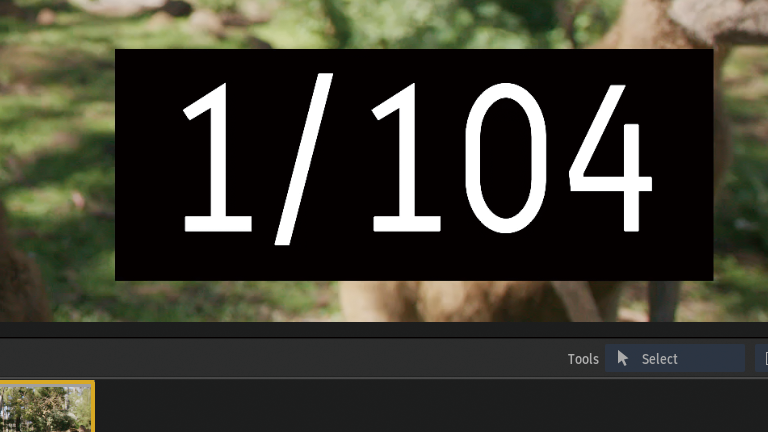
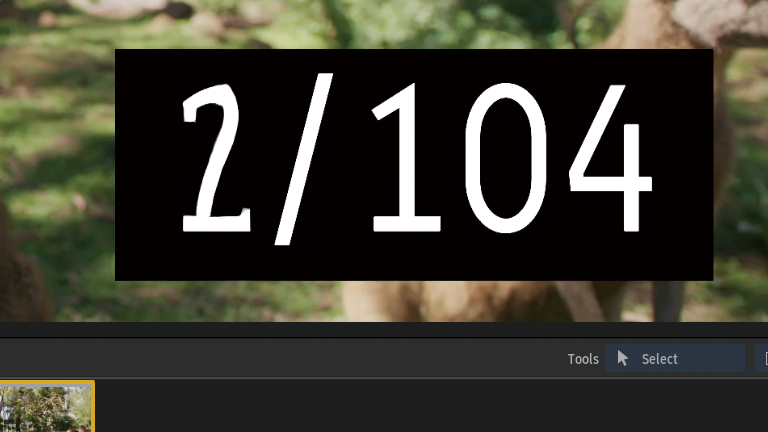
前後のフレームから中間フレームを生成していることがわかります。
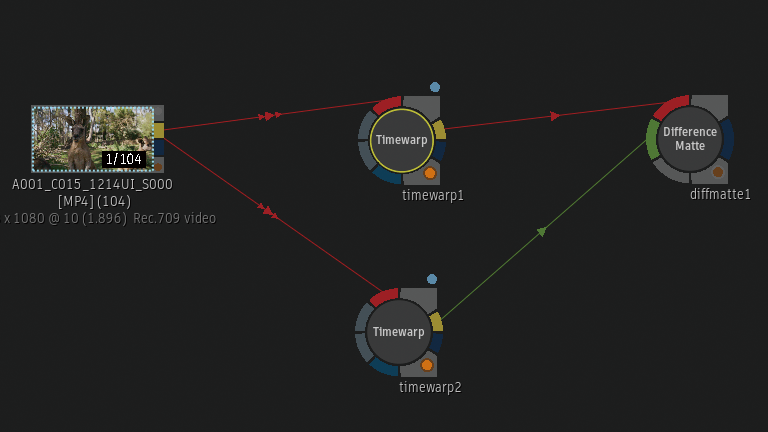
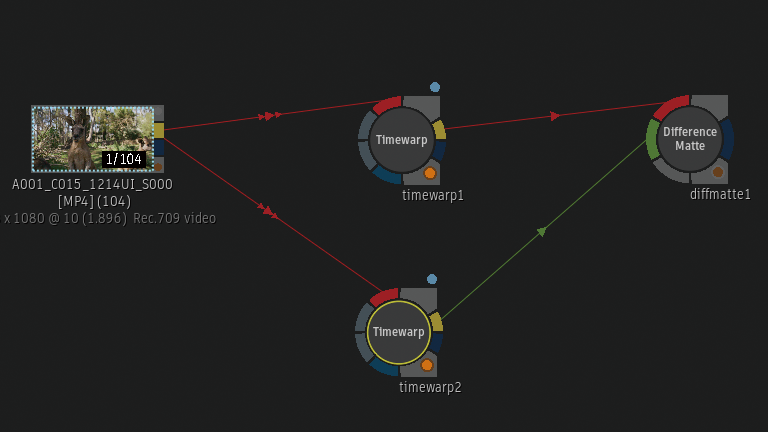
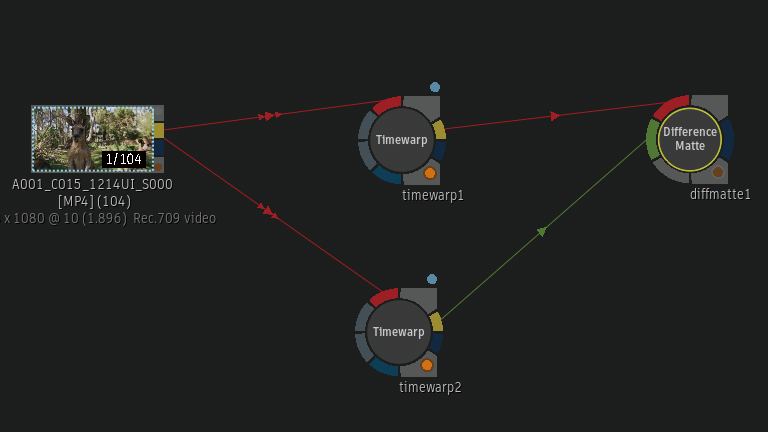
Batchから確認
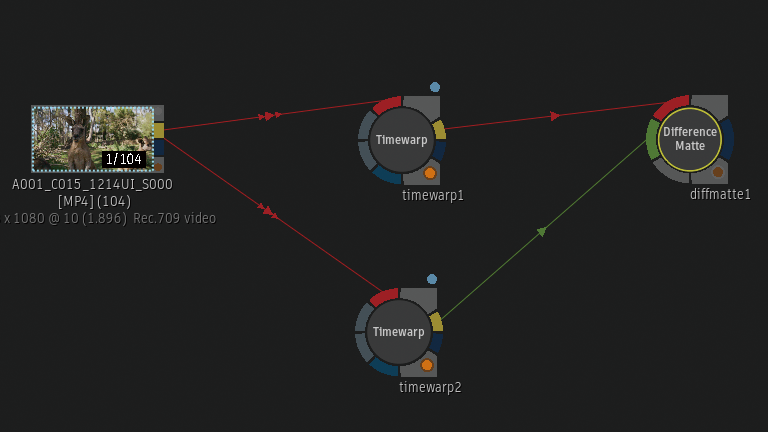
Timewarpノードを2つBatch Schematicに追加しています。上のTimewarpノードはFrame InterpolationがMix。
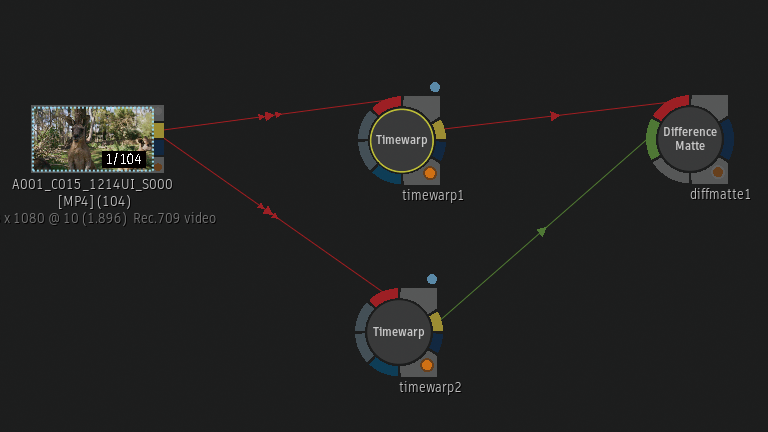
下のTimewarpノードはFrame InterpolationがMachine Learning。
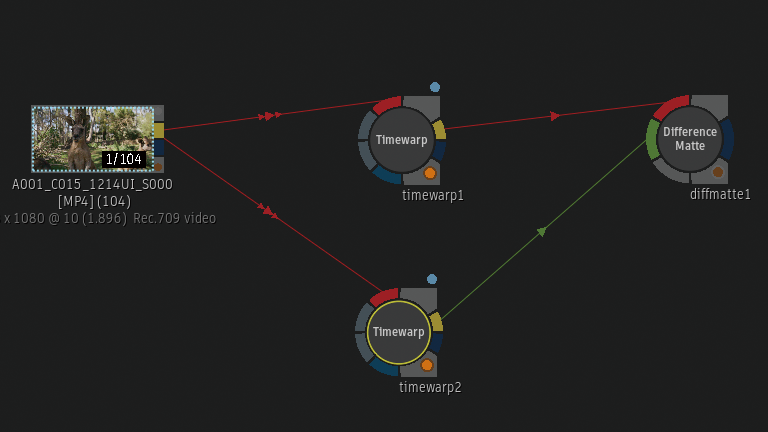
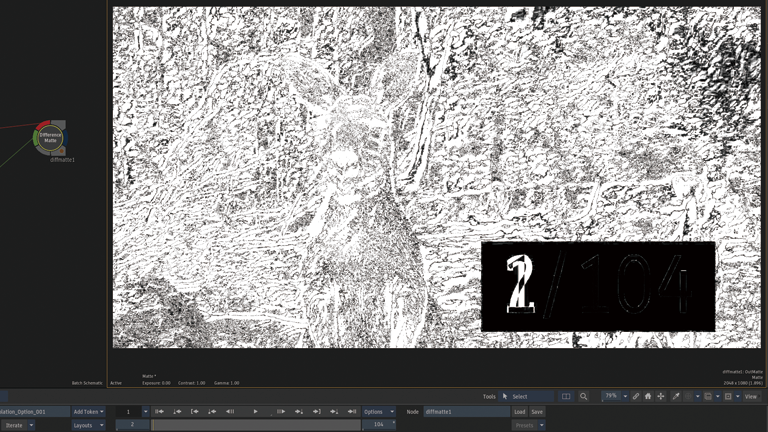
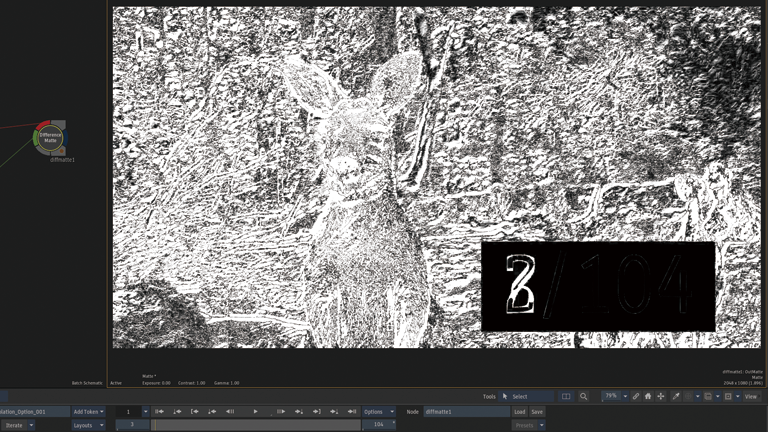
2つのTimewarpノードの差分をDifference Matteから確認。
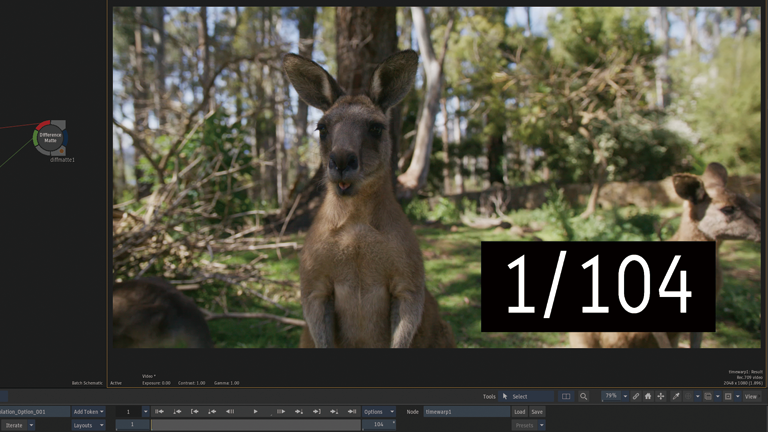
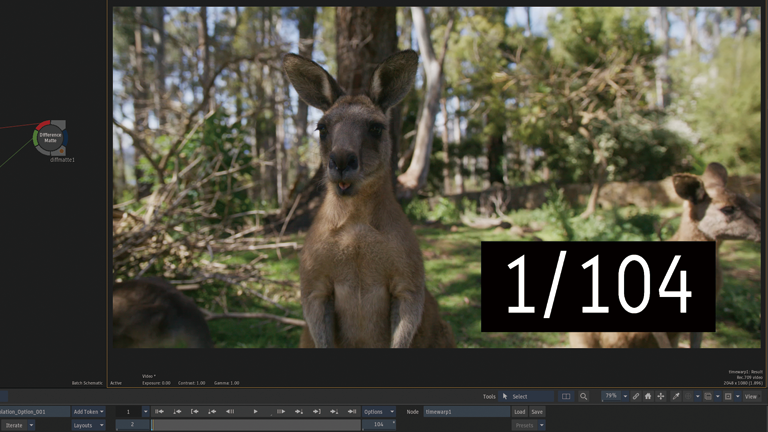
Frame Interpolation > Mix
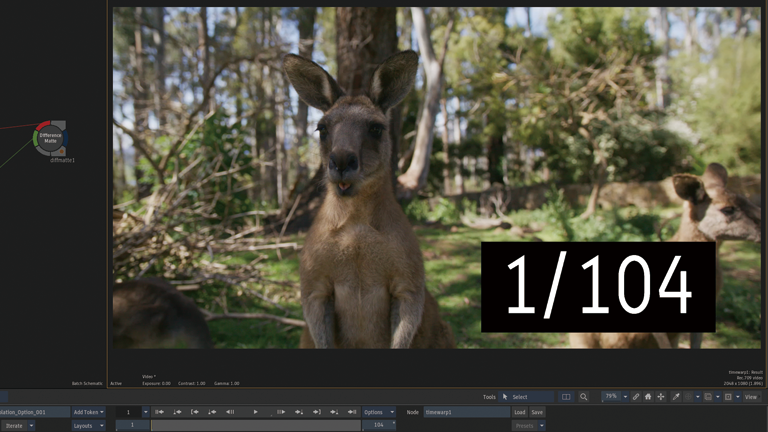
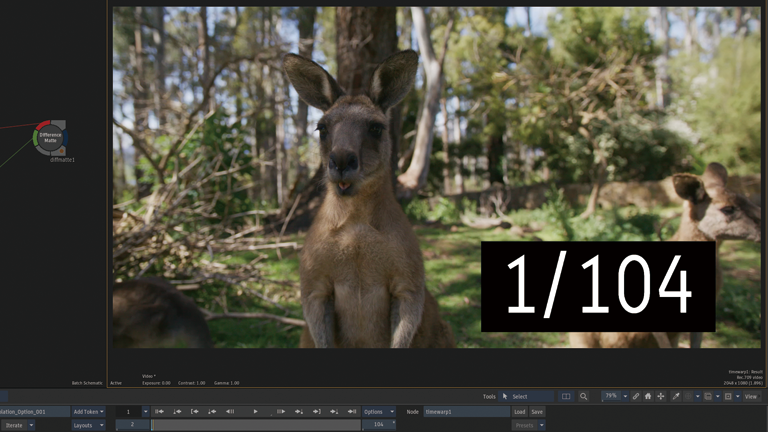
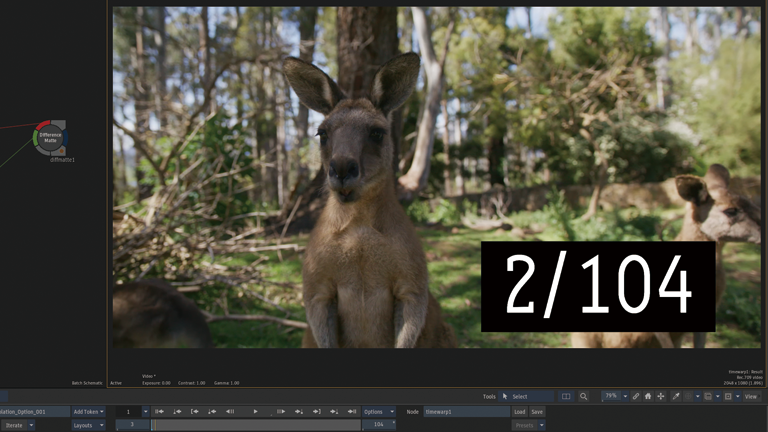
1フレーム目と2フレーム目が同じフレームです。
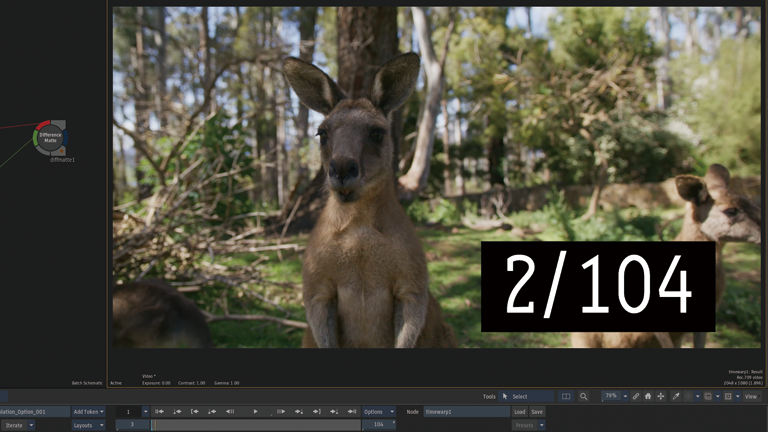
Frame Interpolation > Machine Learning
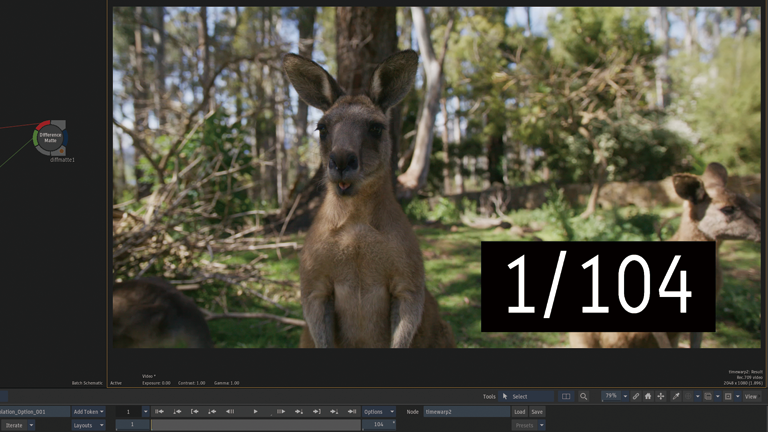
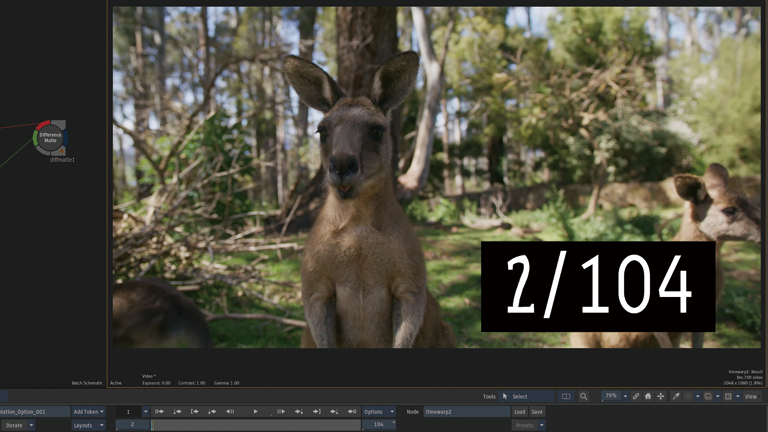
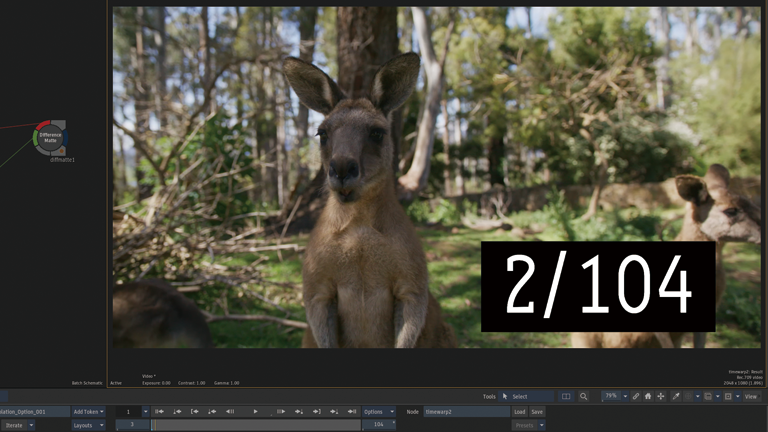
前後のフレームから1つのフレームが生成されています。
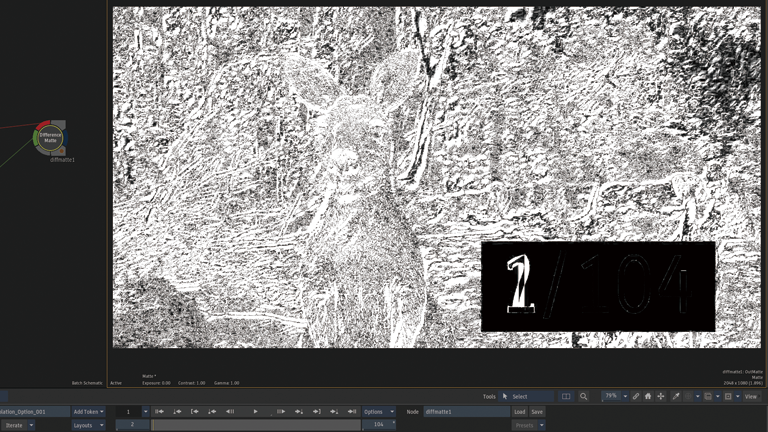
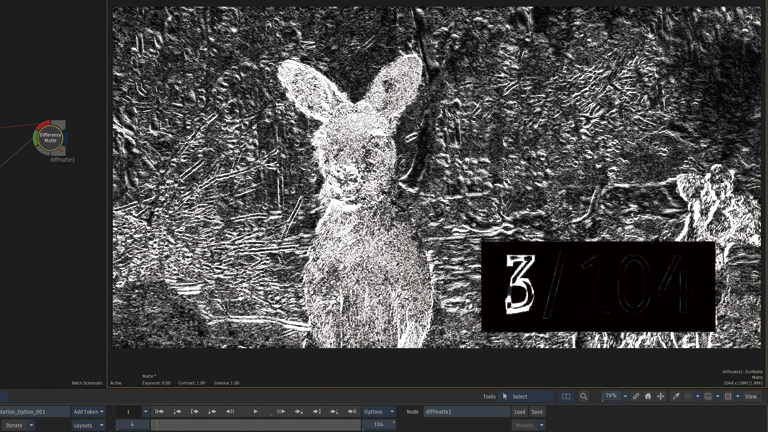
スピードを75%にした場合
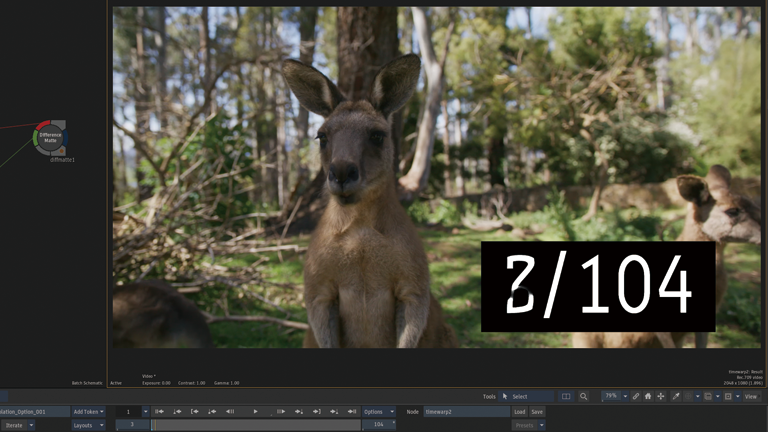
Frame Interpolation > Mix
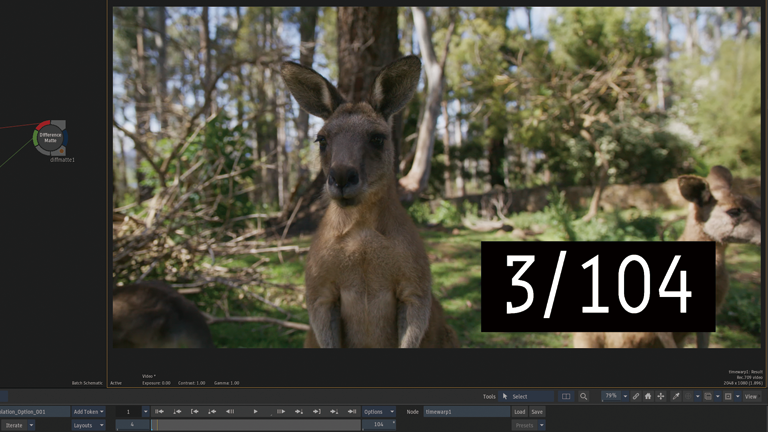

5フレーム周期で1フレーム追加。
Frame Interpolation > Machine Learning
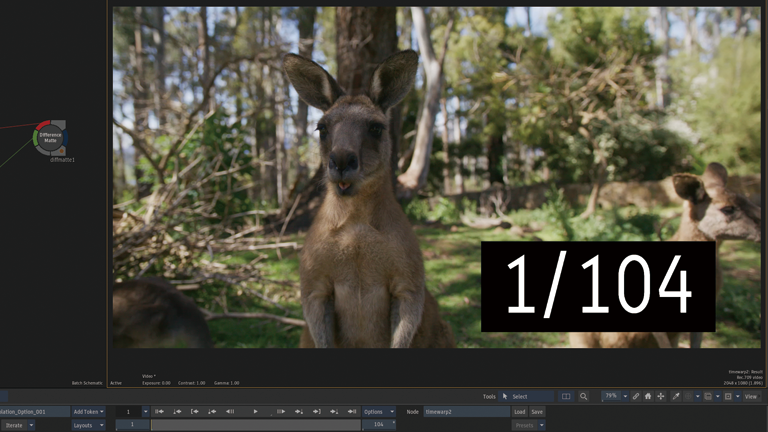
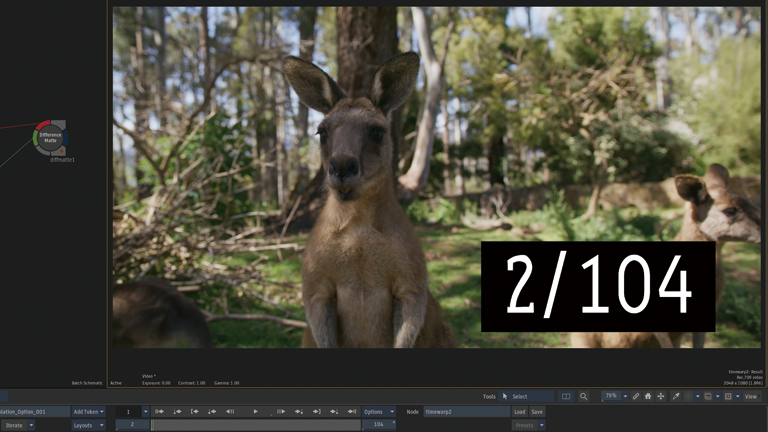
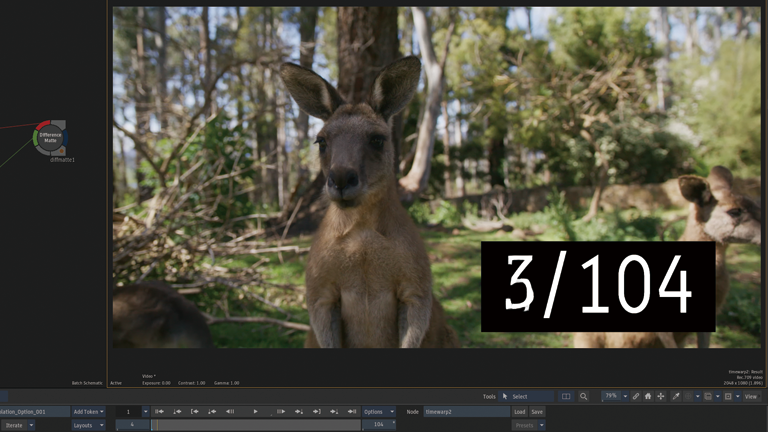

5フレーム周期で3つのフレームを生成。
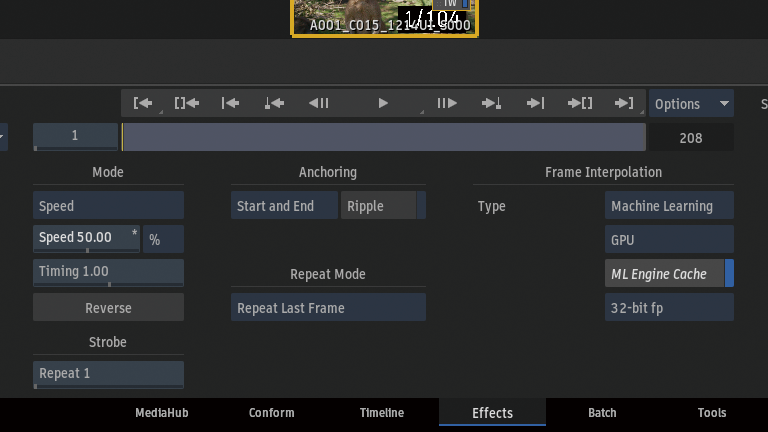
ML Engine Cache
ML Engine Cacheボタンをアクティブにすると、NVIDIA TensorRTキャッシュが有効になります。
NVIDIAが提供するディープラーニング推論を最適化するツールです。学習済みのAIモデルをNVIDIA GPU上で高速かつ効率的に実行します。
Machine Learning inferenceモデル(ML推論モデル)、GPU、および画像サイズの組み合わせごとに新しいTensorRTエンジンが生成されます。
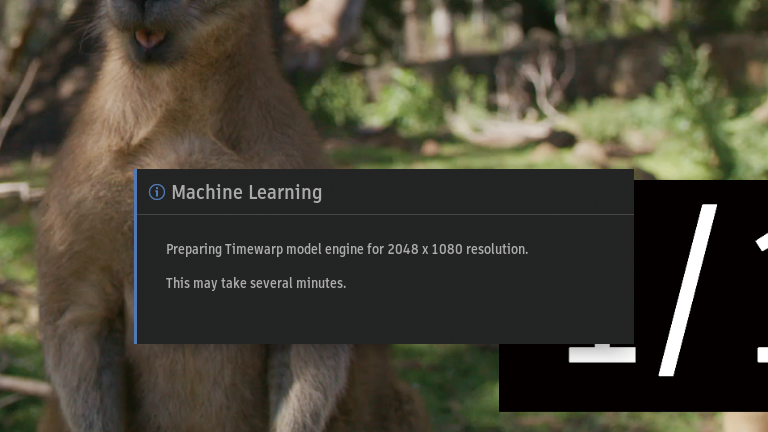
各エンジンキャッシュは、/opt/Autodesk/cache/tensorgraph/modelsに保存され、同じML推論モデル、GPU、および画像サイズの組み合わせが必要になったときに大幅に高速化されます。
[Cafu@Cafu models]$ pwd
/opt/Autodesk/cache/tensorgraph/models
[Cafu@Cafu models]$ ls -l
total 455328
-rw-rw-rw- 1 Cafu Cafu 38593988 Jul 5 2024 2410247SR.bin
-rw-rw-rw- 1 Cafu Cafu 92775988 Jun 11 2024 5696c1bSR.bin
-rw-rw-rw- 1 Cafu Cafu 17978132 Jul 5 2024 72c9074SR.bin
-rw-rw-rw- 1 Cafu Cafu 13150980 May 19 2024 cd22df8SR.bin
-rw-rw-rw- 1 Cafu Cafu 73767284 Jul 5 2024 d301f5dSR.bin
-rw-rw-rw- 1 Cafu Cafu 68125764 Jul 5 2024 dcb339dSR.bin
-rw-rw-rw- 1 Cafu Cafu 73659284 Jul 22 2024 e168a03SR.bin
-rw-rw-rw- 1 Cafu Cafu 88186164 Jul 5 2024 e29b462SR.bin
drwxrwxrwx 2 Cafu Cafu 199 Apr 11 10:21 TWML_fa64789_2048x1088_6960_8.5.3
[Cafu@Cafu models]$